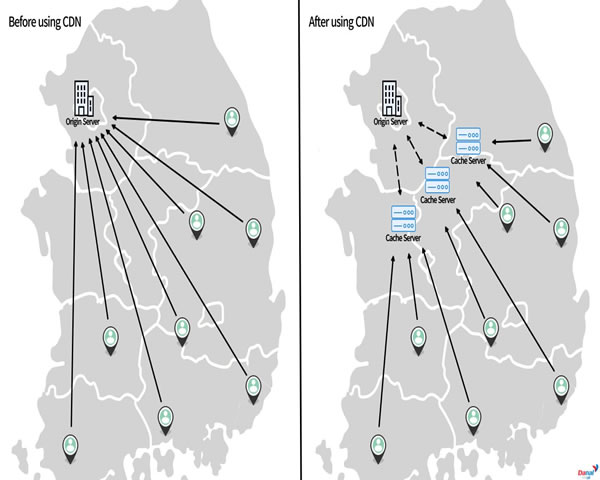
-

合规与合同条款对视频CDN成本的影响以及规避额外费用的方法
2026/6/19 -

经验总结 如何通过准备工作缩短 cdn加速需要多久生效 的时间
2026/6/29 -

用自动化工具审计cdn的流程发现配置偏差与潜在安全风险
2026/7/23 -

cdn 视频压缩 在多分辨率和自适应码流中的应用实践
2026/7/7 -

专家视角剖析cdn在半导体行业中什么意思与成本影响
2026/5/21 -

cdn刷新预热视频是什么在移动端与PC端表现差异及优化方案
2026/5/31
从技术角度解析cDN_B节点失效容错与自动切换实现原理
导言:最好、最佳、最便宜的实现方案简介
在设计CDN_B节点的节点失效容错与自动切换时,最好的方案通常是多层冗余结合主动检测;最佳方案是在成本可控下实现快速恢复与零感知切换;而最便宜的方案则往往依赖于DNS轮询或简单的BGP策略。选择时需兼顾恢复时间(RTO)、数据一致性和实施成本。
什么是CDN_B节点失效容错与自动切换
节点失效容错指当某个CDN边缘或回源节点出现不可用时,系统仍能保证业务连续性;自动切换则是把流量无缝引导到备份节点的过程,常见在服务器、网络层与应用层分别实现不同级别的切换。
检测机制:心跳与主动健康检查
健康检测是触发切换的前提。常见技术包括TCP/HTTP健康检查、应用探针、以及周期性心跳。用心跳检测可以快速判定节点存活,而应用探针能判断业务质量(如页面响应、上游连接)。检测阈值应结合网络抖动与延迟设置。
路由层面的切换实现(BGP/Anycast)
在网络层,采用Anycast配合BGP公告是工业级方案:失效节点撤回路由后流量自动转向其他广告同一前缀的节点。这种方式切换快速且对终端透明,但需要ISP协作与路由收敛时间的考虑。
DNS层面的故障转移
DNS故障转移通过TTL和多记录策略进行。优点成本低、实现简单;缺点是受DNS缓存影响,切换时间不可精确控制。可结合低TTL与主动健康检查减少切换延迟,但会增加DNS查询压力。
负载均衡与流量调度(四层/七层)
使用硬件或软件负载均衡(如LVS、HAProxy、Nginx)可在近端实现流量分发与节点剔除。七层负载均衡能基于内容做更细粒度的路由,四层则在性能上更优。健康检查集成能实现秒级剔除。
会话保持与状态迁移
切换时要考虑会话与状态:无状态服务易于切换;有状态服务需做会话粘滞、分布式会话存储(如Redis)、或状态复制。实时状态同步增加复杂度与网络开销,但能实现无缝切换体验。
故障模式与容错设计策略
常见故障模式包括进程崩溃、网络中断、上游故障和硬件故障。容错设计建议采用多AZ部署、跨机房冗余、独立监控与滚动升级机制,结合自动化运维工具实现故障自动化处理。
自动切换的实现流程
典型流程为:健康检测→判定故障→剔除路由/从LB池移除→流量重定向→监控验证→故障恢复重入。实现时需定义明确的判定策略(如连续失败次数、响应超时阈值)以避免误判。
一致性与数据恢复策略
对于涉及写操作的服务,切换必须保证数据一致性。常见手段有主从复制、分布式事务、幂等设计与冲突解决策略。备份节点应能获取最新数据或采用回写队列在恢复后补偿。
自动化与监控告警体系
自动切换需要可靠的监控与告警来触发。推荐使用Prometheus、Grafana、ELK等工具结合告警规则与自动化脚本(如Ansible、Terraform)完成从检测到执行的闭环。
实现成本与性能权衡
不同方案的成本差异显著:BGP/Anycast和多机房设计成本高但性能最好;软件LB+低TTL DNS成本中等且部署灵活;单纯DNS故障转移最便宜但切换不可控。选择需权衡SLA和预算。
实战建议与常见陷阱
实战建议包括:用红蓝绿或金丝雀发布降低误伤、设置合理的健康检测策略避免抖动、在切换路径上保持日志和追踪;常见陷阱有清理不彻底的会话、忽视路由收敛时间、以及监控盲点。
结语:平衡可靠性与成本
从技术角度看,构建高可用的CDN_B节点失效容错与自动切换,需在网络、负载均衡、会话管理与自动化运维间做平衡。最好的方案未必最适合你,最佳方案是在预算内达到可接受的恢复时间与用户体验,而最便宜的方案适用于对SLA要求不高的场景。